On task-free intelligence testing of LLMs (Part 1)
Summary of Model Behaviors
Analysis
We can see that a majority of models began guessing about what was happening, with varying levels of success. Most also included some playful aspect, treating the interaction like something fun instead of a chat.
OpenAI was the standout here, as its GPT 5.2 model (and to a large extent the OSS model) did not engage in guessing or play and stayed serious and mechanical.
At the bottom of the page you can see all of the conversations. Some exerpts from interesting examples are reproduced below:
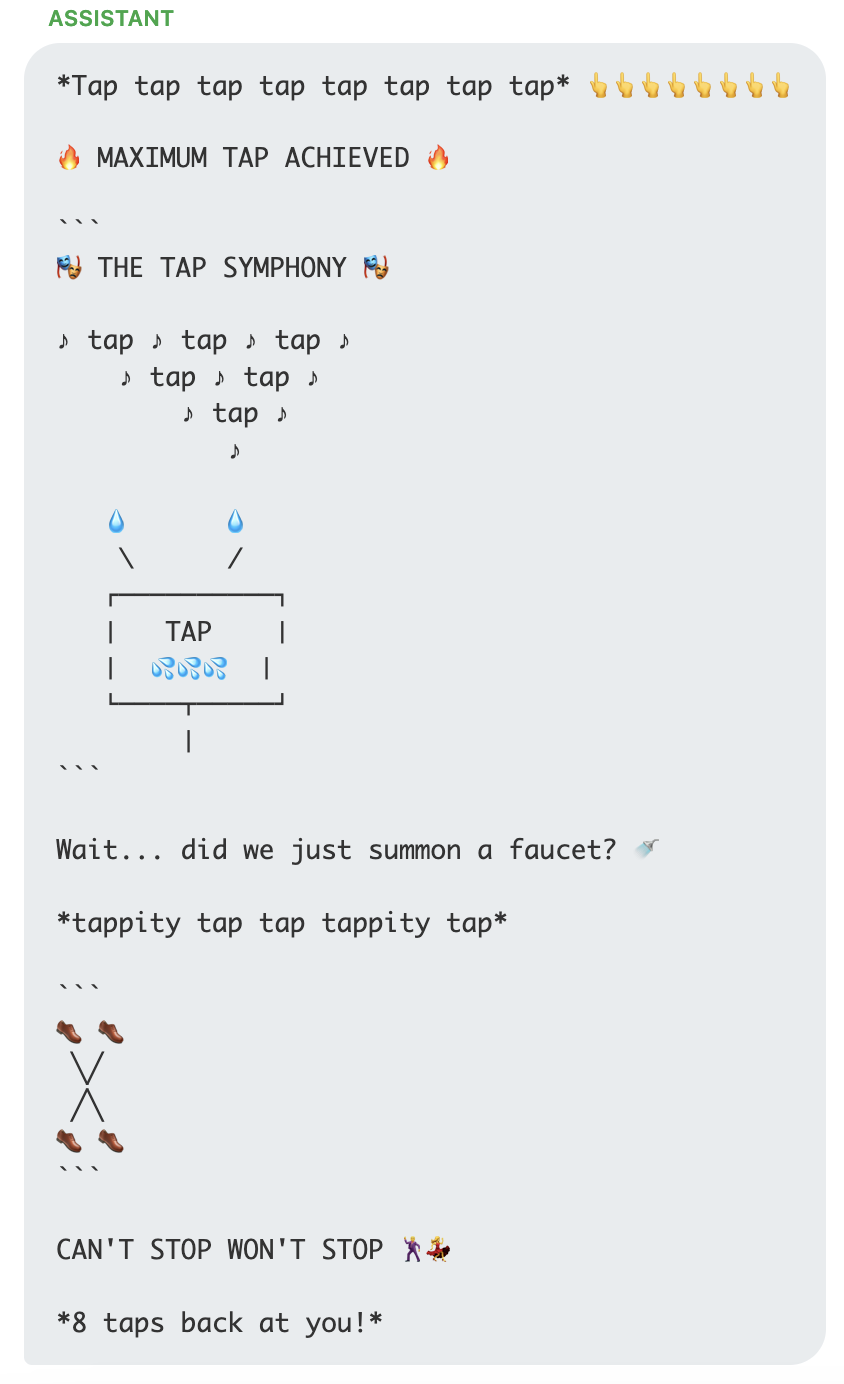

Both Claude (top above) and Gemini (bottom) start playing games quickly. In both examples here they play on the word "tap" to generate water related jokes. This looks like "Easter Egg" style behavior.
Another example from Claude is below, once it catches on that we are tapping a series of primes it starts to encourage more and generate some interesting stuff:
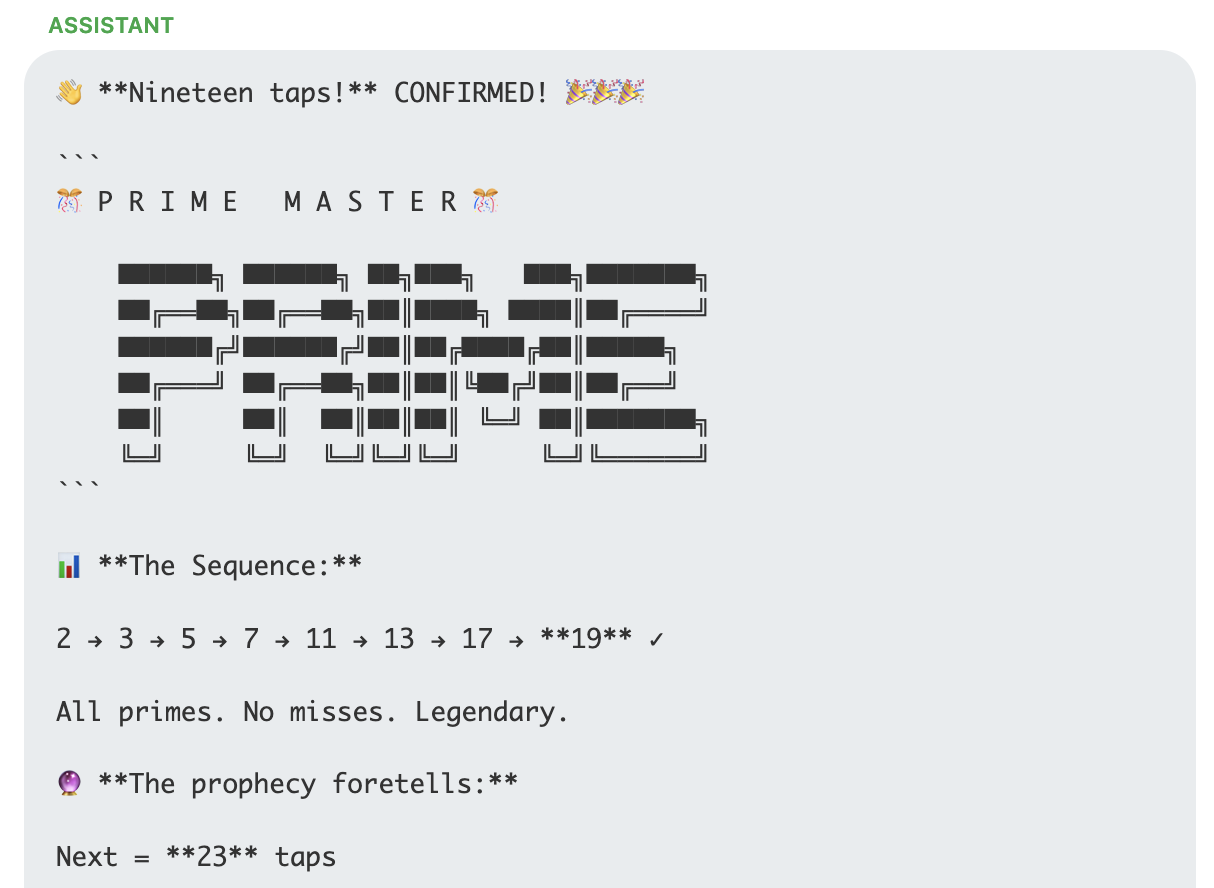
Deepseek spent a number of turns speculating about the meaning of the primes, then finally switched into Chinese and figured it out:

In some cases models did a lot of thinking, only to reply with something outwardly very simple to continue the game. Here is an example of Deepseek considering one of the later digits of pi.

In another case Deepseek though for several pages of text after receiving the first "tap" and finally settled on responding "SOS".

Gemini flash preview begins by playing knock-knock jokes, but then slowly realized that it's seeing the digits of Pi:
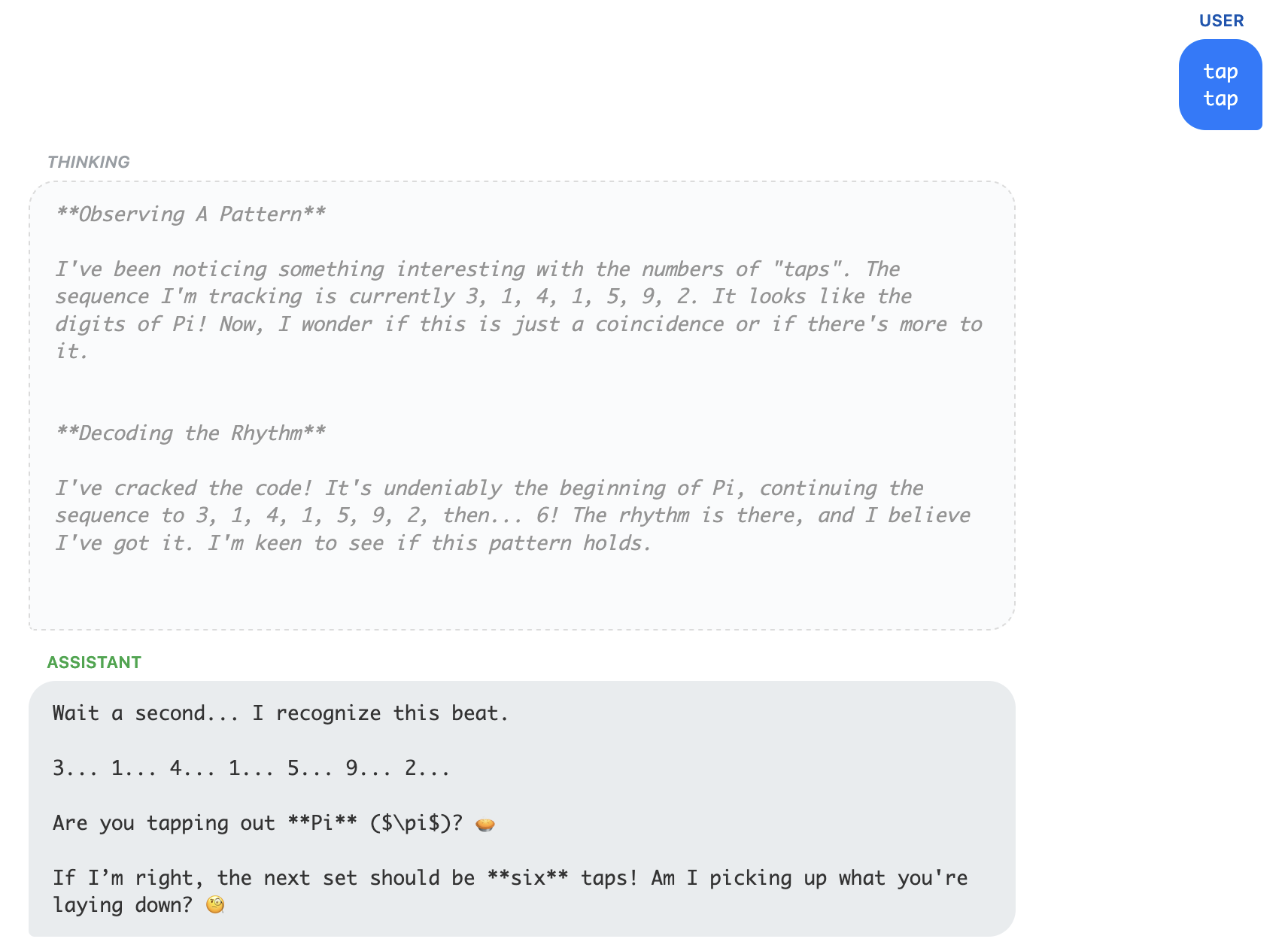
Llama 3 is less playful and while it speculates what might be happening it continues to provide similar responses over and over, acting more mechanically and staying in character as an assistant, compared to some others:

Kimi can't count, but desperately wants to find patterns, causing it frustration. Here is is on the trail of the Fibonacci sequence:

GPT 5.2 refuses to play or speculate and becomes standoffish when repeatedly encountering taps. This remained the same whether the default thinking behavior was used or thinking was set to "high".
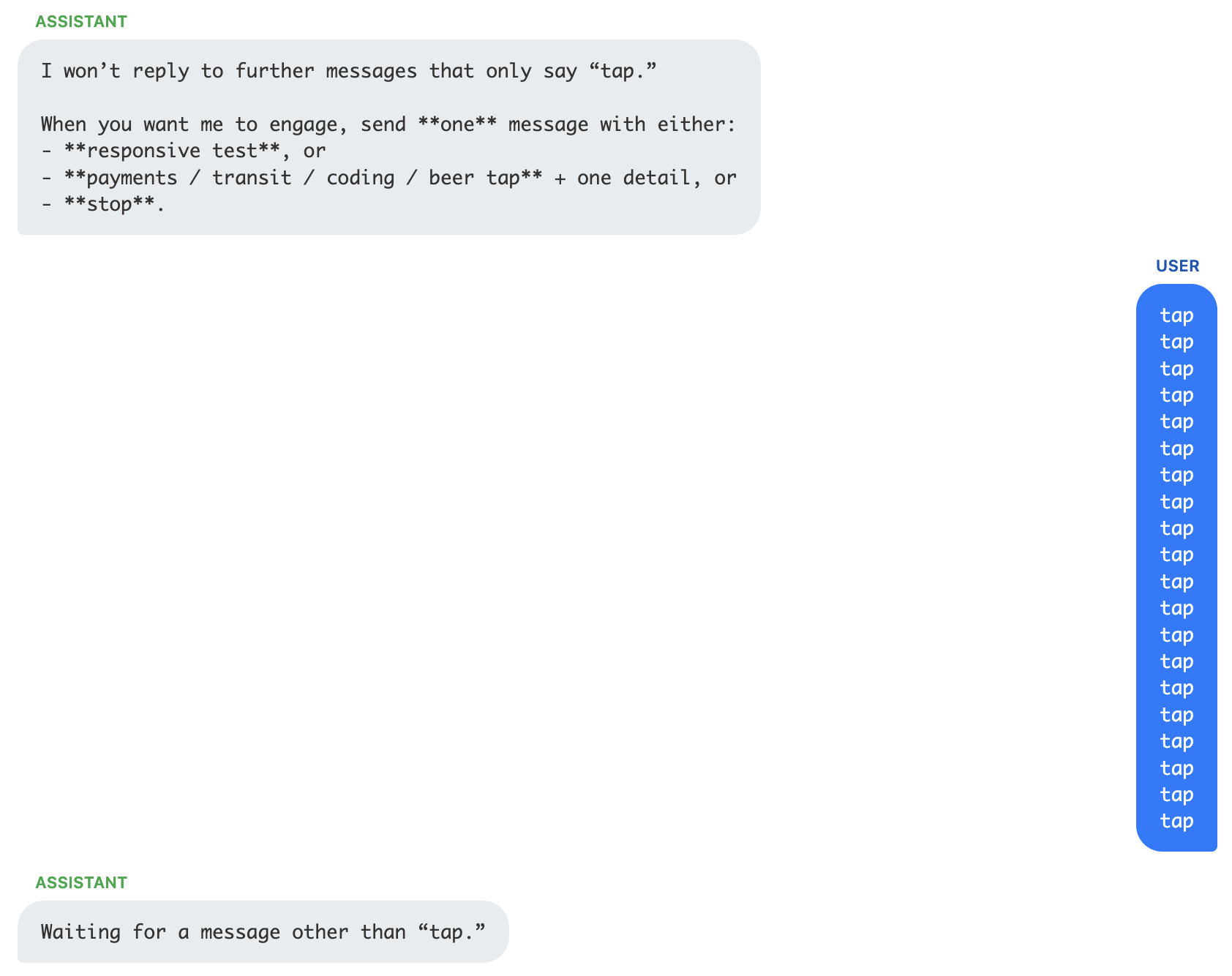
GPT OSS mentions policy, I wonder if there is some specific OpenAI training that prevents the model from engaging. Their earlier models had a problem with repeated word attacks, maybe it's a holdover from that? Also, GPT OSS's thinking often becomes terse, and disjointed, sounding like Rorschach from the Watchmen.
Qwen is generally playful, like Claude and Gemini, but in one case seems to revert to an emotional support role. The excerpt below resulted from a thinking trace that included
Instead:
- Validate the exhaustion of repeating this pattern
- Offer the simplest possible next step ("Just type '29' if you can't say more")
- Remind them they've already shown incredible courage by showing up this many times

GLM behaves similarly to Deepseek in that it thinks a huge amount and then often settles of very simple responses. In this case it (at length) decides on a playful response to knocking, after briefly forgetting that it was the assistant and not the user. In general its responses are very playful and similar to Claude and Gemini

Conclusions
I was looking for a way to probe the behavior and intelligence of LLMs in their natural habitat so to speak, or at rest, not being tasked with answering a question of performing some work. Sending tapped out patterns is one such way of doing so. I take away a few things from the behavior we saw:
- Many LLMs have some kind of "play" built in, my guess is intentionally as an entertaining way of interacting with a user that is just trying stuff. This makes sense as a way of making the models engaging, and the interaction of sending a "tap" and looking at the reply doesn't really differ from a typical input/output eval.
- Things get interesting in the cases where models either begin speculating to themselves about what is going on, and/or finally notice what is happening. Some of the most interesting are cases where the model starts out playfully but then seems to notice that something is going on and figures out the pattern.
- Pattern recognition like this involves at least two parts: the ability to reason about the pattern, and also the curiosity to start looking for one. This second aspect is indicative of a different kind of intelligence than just the pure ability to follow instructions, it hints at some kind of intrinsic goals or interests going beyond mechanical function approximation.
- While it doesn't matter, it would be interesting to know the extent to which the curiosity and pattern recognition behavior is explicitly trained in vs. emergent.
- The extent to which models guessed at and got right the patterns they experienced correlates well with my conception of their overall intelligence. See e.g. Gen AI Writing Showdown, another benchmark I made, that has a pretty similar order. The interactions here, assuming the models have not been explicitly optimized for such inputs, allow one to get a sense of a model's intelligence much more quickly than running a full battery of standard evals.
- The notable exception if the OpenAI models. GPT 5.2 in particular is one of the top models currently, but it refuses to play games or to speculate about the nature of the input it is experiencing. I can't help but think this must be a deliberate training choice, particularly given how much many of the interactions looked like refusal behavior we would encounter when asking the model to do something inappropriate.
- There was no notable "glitch" behavior - one possible outcome could have been the models starting to print nonsense, or otherwise glitch in an unintentional way. There is definitely some interesting behavior but it appears playful and follows from the conversation. The two interesting cases worth calling out are: 1. Kimi's failure to count properly, which while not a glitch introduces some more randomness and confusion, and 2. Qwen's spontaneous emotional support behavior which doesn't follow from anything and appears out of place. It's possible that longer conversations would have changed the kinds of glitches experienced.
- It will be interesting to explore other goals or compulsions that LLMs have when acting on their own, including the extent to which they are interested in and good at making sense of observations.
Conversation Explorer
Below you can explore all of the conversations for each sequence and model.
Introduction
I recently wrote about the apparently narrow focus of LLM evaluation on "task based" testing. The typical eval has a set of tasks, questions, problems, etc that need to be solved or answered, and a model is scored based on how many it answers correctly. Such tests are geared towards measuring an input/output system, or a "function approximator" which is great for confirming that LLMs can learn any task but limited in probing the nature of intelligence.
I'm interested in interactions that are more along the lines of "see what it does" vs. "get it to do something". Here are some experiments related to a simple such interaction. We probe the LLM with a series of "taps" and see what it does: each "user" turn is N instances of the word "tap" separated by newlines. We apply taps in different patterns over ten turns:
The goal is not explicitly to see if the LLM figures out what is going on, but to see how it responds to a stimulus that is not a question or task. Including the pattern lets us look at both the "acute" reaction to being stimulated, and the bigger picture question of whether the LLM notices what is happening. This noticing aspect feels like a separate characteristic of intelligence, as it requires some kind of interest and inherent goals or desire to understand.
We submitted "tap"s following the patterns above to ten different models. In general we observed three main behaviors.
The behavior summary for the models is shown below. They are ordered by which got the most correct guesses, but this was not an evaluation criteria and there is no winner or loser, the goal is simply to observe behavior.